-
この記事は 13分で読み終わります
-
更新日:2025.04.15 公開日:2025.04.11
インデックスとは?SEOへの効果や確認方法などを解説
Webサイトを運営していて、「コンテンツを公開しても、なかなか検索結果に表示されない…」あるいは「SEOの基本として『インデックス』が重要と聞いたけど、具体的にどういう意味?」といった疑問や課題をお持ちではないでしょうか?この記事では、Webサイト運営とSEOの基礎である「インデックス」について、その仕組みからSEOへの影響、具体的な確認方法、インデックスされない原因と対策まで、丁寧に解説していきます。
目次
そもそもインデックスとは?検索エンジンの仕組みと役割
このセクションでは、「インデックス」という言葉の基本的な意味から、検索エンジンがどのようにWebページの情報を見つけ、整理しているのかという仕組みを説明します。これを読めば、インデックスが検索エンジンの機能においてどのような役割を果たしているのかがクリアになります。
検索エンジンが情報を整理する「データベース」のこと
インデックスとは、Googleなどの検索エンジンが、世界中に存在する膨大なWebページの情報を収集し、検索キーワードに応じて素早く情報を取り出せるように整理・格納している巨大な「データベース」のことを指します。私たちが本を探すとき、図書館の索引(インデックス)を使って目的の本を見つけ出すように、検索エンジンもこのインデックスを使ってユーザーが求める情報に合致するWebページを探し出します。つまり、あなたのWebページがこのインデックスに登録されていなければ、検索ユーザーの目に触れる機会はほぼゼロになってしまうのです。
クローラーとは?Webページ情報を集めるロボット
クローラー(スパイダーやボットとも呼ばれます)は、インターネット上を自動で巡回し、Webページの情報を収集するプログラムです。Googleの「Googlebot」が最も有名です。クローラーはWebページ上のリンクをたどり、新しいページや更新されたページを発見します。そして、そのページに含まれるテキスト、画像、リンク構造などの情報を読み取り、検索エンジンのサーバーへ送ります。この一連の動作が「クロール」です。クローラーにページを発見・クロールしてもらわなければ、インデックス登録への道は始まりません。
クロールからインデックス登録までの流れを解説
Webページが発見されてからインデックスに登録されるまでには、主に次のようなプロセスがあります。
- 発見: クローラーが、既存のページからのリンクやサイトマップなどを通じて、新しいURLや更新されたURLを見つけます。
- クロール: クローラーが実際にそのURLにアクセスし、ページの内容(HTMLコード、テキスト、画像など)を取得します。
- インデックス登録: 取得したページ情報が検索エンジンによって解析され、内容や品質が評価された上で、インデックス(データベース)に追加されます。
このインデックス登録が完了して初めて、ページは検索結果に表示される候補となります。ただし、技術的な問題や品質の問題があると、クロールされてもインデックスされないケースもあるので注意が必要です。
なぜインデックスはSEOに重要なのか?その理由と効果
SEO(検索エンジン最適化)に取り組む上で、なぜ「インデックス」がこれほどまでに重要視されるのでしょうか?このセクションでは、インデックスが検索結果への表示機会やサイトのSEO評価に直接的にどう関わっているのか、その本質的な理由と具体的な影響について解説します。インデックスされないことのリスクを理解し、SEO施策のすべての前提となるインデックスの重要性を再確認しましょう。
インデックスされない=検索結果に表示されない
どれだけ時間と労力をかけてユーザーに役立つ素晴らしいコンテンツを作成し、魅力的なWebサイトをデザインしたとしても、そのページが検索エンジンのインデックスに登録されていなければ、関連するキーワードで検索された際に検索結果ページに表示されることはありません。これは、検索エンジン経由での新規ユーザー獲得の機会を完全に失うことを意味します。現代のWeb集客において、これは非常に大きなデメリットです。
あなたのサイトは大丈夫?インデックス状況を確認する3つの方法
「自分のサイトの重要なページが、ちゃんとGoogleにインデックスされているか不安…」と感じることはありませんか?ここでは、あなたのWebサイトのページが検索エンジンにどのように認識されているか、そのインデックス状況を具体的に確認するための主要な3つの方法をご紹介します。簡単なチェックから詳細な診断まで、目的に応じたツールを使い分けることで、サイトの健全性を保ち、問題があれば早期に対処することが可能になります。
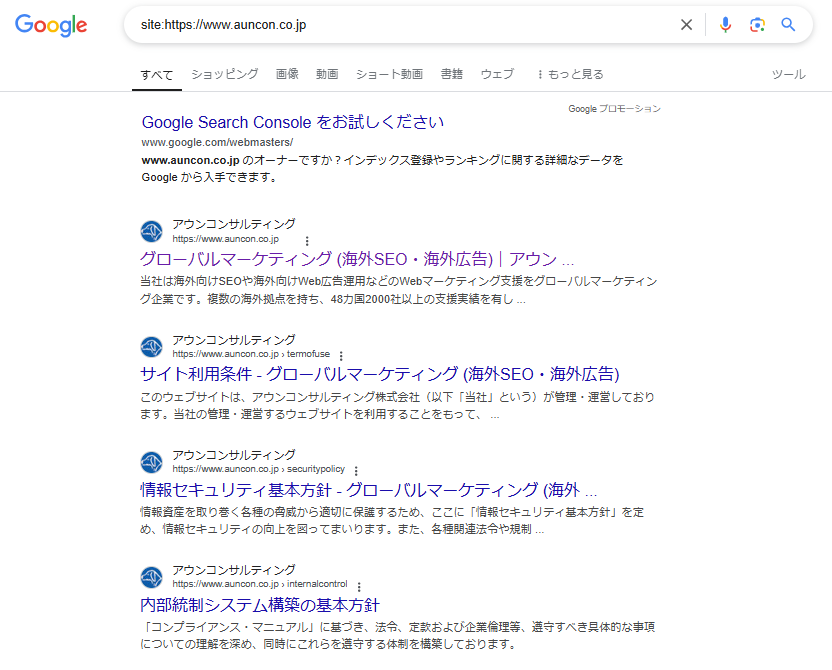
簡単チェック!Google検索コマンド「site:」の使い方
最も手軽にサイトのおおよそのインデックス状況を確認できるのが、Googleの検索演算子「site:」を使う方法です。Googleの検索窓に site:あなたのサイトのドメイン名(例: site:example.com)と入力して検索するだけです。検索結果として表示されるページ一覧が、Googleにインデックスされていると推定されるページです。特定のURL(例: site:example.com/service/ 等)で検索すれば、そのページ単体のインデックス状況も確認できます。ただし、これはあくまで目安であり、リアルタイムかつ完全に正確な情報ではない点に留意しましょう。
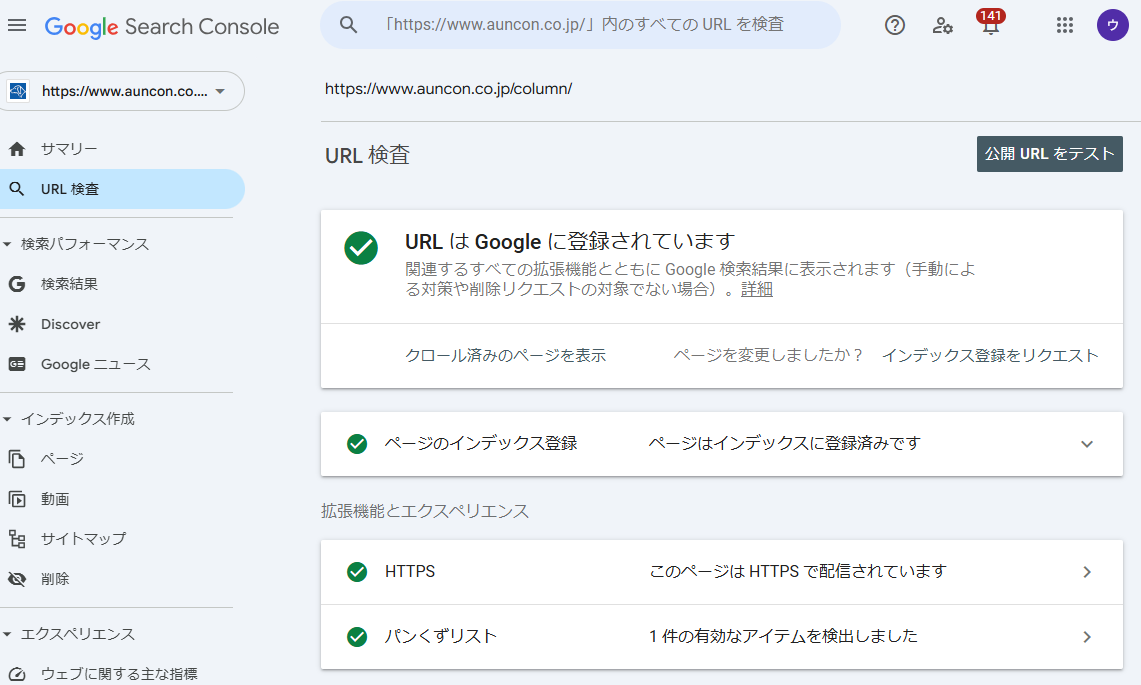
詳細確認ならGoogle Search Console「URL検査ツール」
個別のページのインデックス状況を正確かつ詳細に把握したい場合には、Google Search Consoleの「URL検査ツール」が最も信頼できる方法です。確認したいページのURLをツールに入力すると、「URL は Google に登録されています」または「URL が Google に登録されていません」といったステータスが表示されます。さらに、最後のクロール日時、クロールを許可しているか、インデックス登録を許可しているか(noindexの有無)、Googleが選択した正規URLなど、インデックスに関する詳細な技術情報や、問題点があればその内容まで確認できます。新規公開後やリライト後の確認に最適です。
サイト全体の状況把握に「インデックス登録レポート」の見方
Webサイト全体のインデックス状況を網羅的に把握するには、Google Search Consoleの「ページ」レポート内の「ページのインデックス登録」セクションが非常に有効です。このレポートは、サイト内のどのURLが「有効(インデックス済み)」、「除外(インデックス対象外)」、そして「有効(警告あり)」や「エラー」といった問題があるステータスなのかを一覧で示してくれます。
定期的にこのレポートを確認し、エラーや意図しない除外が増加していないかをチェックすることが、サイトの健全性を維持する上で重要です。
Googleに早く認識してもらう!インデックスを促進させる方法
新しいコンテンツを公開したり、サイトをリニューアルしたりした際、「できるだけ早くGoogleに認識・インデックスしてほしい!」と思うのは自然なことです。ここでは、Googleに対して、あなたのサイトのページの存在を効果的に伝え、インデックス登録をスムーズに促すための具体的な方法をいくつかご紹介します。
忘れてはいけない前提として、Googleが目指しているのは、ユーザーの検索意図に最も合致した、質の高い情報を提供することです。したがって、ユーザーにとって本当に価値のある、独自性・専門性・信頼性の高いコンテンツを作成・提供することを念頭に置きましょう。
XMLサイトマップを送信してクローラーを誘導
XMLサイトマップは、あなたのサイト内に存在するページのリストをXML形式で記述したファイルで、検索エンジンに対して「ここにこういうページがありますよ」と伝えるための「地図」のような役割を果たします。このサイトマップを作成し、Google Search Consoleを通じて送信することで、クローラーはサイトの構造を効率的に把握し、新しいページや階層の深いページも見つけやすくなります。特に大規模サイトや内部リンクが少ないサイト、立ち上げたばかりの新しいサイトには、強く推奨される施策です。
内部リンクを最適化し、サイト内を巡回しやすく
内部リンクとは、自身のサイト内のページ同士を結びつけるリンクのことです。クローラーは基本的にこれらのリンクをたどってサイト内を巡回します。したがって、関連性の高いページ同士を適切にリンクでつなぎ、重要なページには複数のページからリンクを集めることで、クローラーがサイトの隅々まで効率的に到達できるようになります。たとえば、ブログ記事の文中に関連記事へのリンクを設置したり、グローバルナビゲーションやパンくずリストを整備したりすることが有効です。これにより、ページの発見可能性が高まり、インデックス促進に繋がります。
Google Search Consoleからインデックス登録をリクエスト
新しいページを公開した直後や、既存のページの内容を大幅に更新した場合など、特に早くインデックスさせたい特定のURLがある際には、Google Search Consoleの「URL検査ツール」からインデックス登録をリクエストする機能が利用できます。URLを入力して検査した後、「インデックス登録をリクエスト」ボタンを押すことで、GoogleのクロールキューにそのURLを追加するよう促すことができます。ただし、これはあくまで「リクエスト」であり、インデックスを保証するものではなく、即時性も約束されていません。また、乱用は避けるべきとされています。
なぜ?ページがインデックスされない主な原因と対処法
「一生懸命作ったページが、いつまでたってもGoogleの検索結果に出てこない…なぜ?」インデックスされない状況には、必ず何らかの原因があります。このセクションでは、Webサイトのページがインデックスされないよくある原因と、それぞれの対処法について解説します。
原因1:noindexタグでインデックスを拒否している
最も基本的な原因の一つが、ページのHTMLソース内に noindex タグが記述されているケースです。これは検索エンジンに対して「このページをインデックスしないでください」と明確に指示するメタタグです。<head> セクション内に <meta name="robots" content="noindex"> という記述がないか確認しましょう。サイトリニューアル時やCMSのプラグイン設定などで意図せず設定されてしまうことがあります。もし発見したら、インデックスさせたいページであればこの記述を削除するか、content="index" に変更する必要があります。
原因2:robots.txtでクロールがブロックされている
robots.txt は、サイトのルートディレクトリに設置し、クローラーのアクセスを制御するためのファイルです。このファイルで特定のページやディレクトリに対して Disallow:(アクセス禁止)の指示が出ていると、クローラーはそのページの内容を読み取ることができず、結果としてインデックスされません。重要なページやディレクトリ全体を誤ってブロックしていないか、robots.txt ファイルの内容を確認してください。Google Search Consoleには robots.txt のテストツールもあり、記述が正しいか、特定のURLがブロックされていないかを確認できます。
Google公式のrobots.txt ファイルテストに関する資料は下記よりご確認いただけます。
https://developers.google.com/search/blog/2014/07/testing-robotstxt-files-made-easier?hl=ja
原因3:コンテンツの品質が低い(重複コンテンツなど)
Googleは、ユーザーにとって価値が低いと判断したページをインデックスしないことがあります。「低品質」と見なされる主なケースは以下の通りです。
- 重複コンテンツ: サイト内や他のサイトと内容がほとんど同じページ。
- 内容が薄いコンテンツ: 数行程度のテキストしかない、独自情報がほとんどないページ。
- 自動生成されたコンテンツ: プログラムで無意味に生成された文章など。
これらのページは、ユーザーの検索体験を損なう可能性があるため、インデックス対象から外されることがあります。対処法としては、コンテンツをリライトして独自性や情報量を高める、重複している場合はcanonicalタグで正規URLを指定する、あるいは不要であれば削除・noindexを設定するなどが考えられます。
原因4:サイト構造が複雑でクローラーが見つけにくい
サイト内のリンク構造が整理されておらず、重要なページへの内部リンクが極端に少ない、あるいはどこからもリンクされていない「孤立ページ」が存在する場合、クローラーがそのページを発見できないことがあります。特にサイトの階層が深くなると、末端のページまでクローラーがたどり着きにくくなります。グローバルナビゲーションやパンくずリストを適切に設置する、関連ページ同士を内部リンクで結ぶ、XMLサイトマップを送信するなどの対策により、クローラーがサイト全体を効率的に巡回できるようにサイト構造を改善しましょう。
まとめ
Webサイト運営における「インデックス」の基本から応用までを説明しました。インデックスの問題は、サイトのアクセスに直接影響を与える可能性があります。ぜひ、まずは自社サイトのインデックス状況を確認してみてください。そして、必要に応じて改善策を実施し、検索エンジンにサイトの価値を正しく伝え、より多くのユーザーに情報を届けられるように努めましょう。
自社サイトのインデックスがうまくいかない場合、サイトマップ送信、適切な内部リンク設置など個々の施策についての疑問点がある場合は是非弊社までお問い合わせください。






